Prometheus 和 Grafana 服务搭建
prometheus服务监控
注:文档仅记录在linux下进行的一系列操作;
安装前准备:
- 安装wget,用于下载文件,命令:
yum install wget -y
- 安装lrzsz,用于上传文件资料,命令:
yum install lrzsz -y
- 如果要跨机器访问需要开启端口号,在root用户下使用命令(0000表示要开启的端口号):
firewall-cmd --zone=public --add-port=0000/tcp --permanent
重启防火墙:
firewall-cmd --reload
Prometheus介绍:
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。 表示维度的标签可能来源于你的监控对象的状态,比如code=404或者content_path=/api/path。也可能来源于的你的环境定义,比如environment=produment。基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围
- 预测在4小时后,磁盘空间占用大致会是什么情况
- CPU占用率前5位的服务有哪些(过滤)
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
- 数以百万的监控指标
- 每秒处理数十万的数据点
Prometheus生态结构:
Prometheus 生态结构图如下所示:
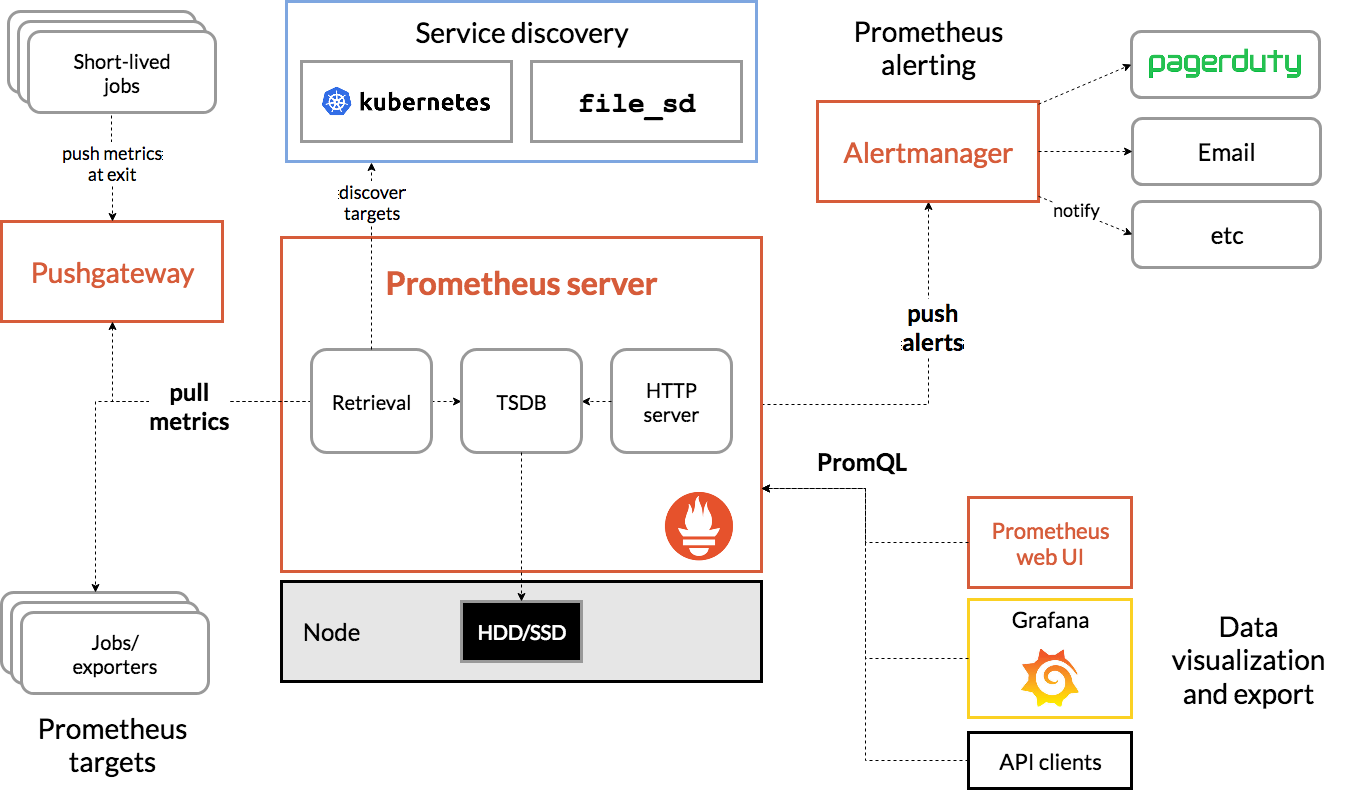
prometheus 获取服务数据的方式有两种:pull和push两种模式,默认支持pull模式,配置简单,操作容易,配合一系列的Exporter可以很容易获取metircs接口数据,push模式需要pushgateway的支持,且需要自己实现一些操作,包括数据添加、更新、删除操作的数据到prometheus的pushgateway中,官方对push模式这样说的:


使用Pushgateway有几个陷阱:
- 通过单个Pushgateway监控多个实例时,Pushgateway成为单点故障和潜在瓶颈。
- 您通过up 指标(每次刮除时生成)丢失了Prometheus的自动实例运行状况监控。
- Pushgateway永远不会忘记推送到它的系列,并将永远暴露给Prometheus,除非这些系列是通过Pushgateway的API手动删除的。
Prometheus对比Zabbix:
| Zabbix | Prometheus |
|---|---|
| 后端用C开发,界面用PHP开发,定制化难度很高。 | 后端用golang开发,前端是Grafana,JSON编辑即可解决定制化难度较低 |
| 集群规模上限为 10000 个节点 | 支持更大的集群规模,速度也更快 |
| 更适合监控物理机环境 | 更适合云环境的监控,对OpenStack,Kubernetes有更好的集成 |
| 监控数据存储在关系型数据库内,如 MySQL,很难从现有数据中扩展维度 | 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合 |
| 安装简单,zabbix-server 一个软件包中包括了所有的服务端功能 | 安装相对复杂,监控、告警和界面都分属于不同的组件 |
| 图形化界面比较成熟,界面上基本上能完成全部的配置操作 | 界面相对较弱,很多配置需要修改配置文件 |
| 发展时间更长,对于很多监控场景,都有现成的解决方案 | 2015 年后开始快速发展,但发展时间较短,成熟度不及Zabbix |
Prometheus工作流程:
1、Prometheus Server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Push Gateway 发过来的 metrics,或者从其他的 Prometheus Server 中拉 metrics。 2、Prometheus Server 在本地存储收集到的 metrics,并运行已定义好的预警规则,记录新的时间序列或者向 Alertmanager 推送警报。 3、Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。 4、在图形界面(Grafana)中,采集数据,将其可视化。
Prometheus客户端库主要提供四种主要的 metric 类型:
- Counter(计数器): - 说明:Counter是一个累积度量,它表示一个单调递增的 Metrics,其值只能在重启时递增或重置为零; - 场景:可以使用Counter来表示http的请求数、已完成的任务数或错误数、下单数。
- Gauge(测量仪): - 说明:当前值的一次快照(snapshot)测量,可增可减。 - 场景:磁盘使用率,当前同时在线用户数。
- Histogram(直方图): - 说明:通过区间统计样本分布。 - 场景:请求延迟时间的统计。例如统计 0200ms、200ms400ms、400ms~800ms 区间的请求数有多。
- Summary(汇总): - 说明:根据样本统计出百分位。 - 场景:请求延迟时间的统计。例如统计 95%的请求延迟 < xxx ms ,99%的请求延迟 < xxx ms。
Prometheus安装:
- 下载prometheus文件,在Linux系统中,使用cd命令进入目标目录下,例如:/usr/local/src/prometheus;下载链接为:https://prometheus.io/download/ 如图所示,下载红色框中的文件:

- 解压下载文件,使用tar -zxvf prometheus-*.tar.gz命令进行解压缩。解压后如下图所示,红色框中的为执行文件:

- 进入到premotheus根目录下,执行命令:sudo ./Prometheus 启动服务(启动prometheus需要/prometheus/data权限),可以看到下图所示信息即表示启动成功;
另外后台启动服务使用命令:nohup ./prometheus > prometheus.log 2>&1 & 启动之后,浏览器输入http://192.168.xx.xx:9090 ,如下如所示:
在阿里云的ESC部署的时候发现的问题及解决办法:
- 按照上面的操作进行启动的时候报错,报错信息如下:
level=error ts=2019-07-23T02:03:30.555Z caller=main.go:731 err=“opening storage failed: lock DB directory: resource temporarily unavailable”
解决办法:删除解压目录下的 lock 文件 执行:
rm -f \[软件的本地解压目录\]/prometheus/data/lock
- 解决上面的问题后,启动服务发现还有报错,报错信息如下:
level=error ts=2019-07-23T02:30:49.107Z caller=main.go:731 err=“error starting web server: listen tcp 0.0.0.0:9090: bind: address already in use”
解决办法:查找占用9090端口的应用的PID,然后强制关闭 执行:
sudo netstat -antup
查找到占用9090端口的应用的PID 执行:
kill -9 \[具体的pid\]
Prometheus配置介绍:
Prometheus配置只有一个prometheus.yml文件,其内容如下图所示:
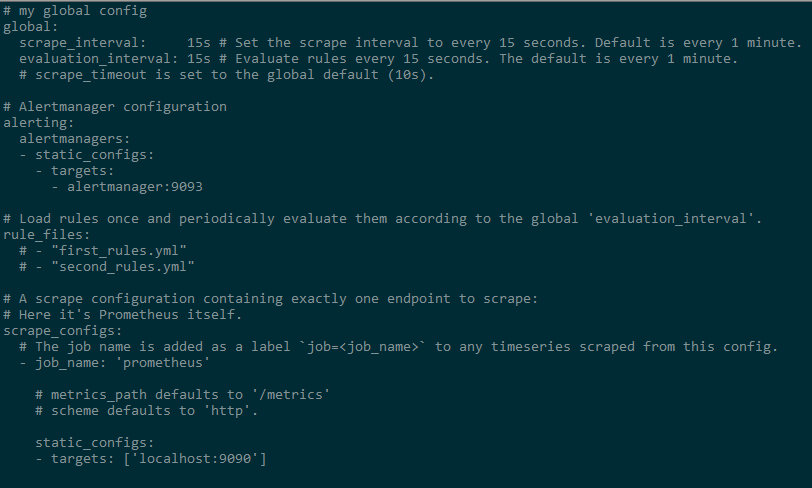
读配置文件即其中的注释可以知道默认的配置有四个,global全局配置,alerting预警,rule_files规则文件,scrape_configs下载配置;
在scrage_configs下看到默认配置了prometheus自己的监控配置,job_name是一个配置标识, static_config下有一个targets,这个配置监控服务的地址+端口号,promehteus会通过这个配置的url和默认的路径”/metrics”,去对应的服务上pull监控的各种数据到prometheus中进行存储。
Prometheus数据存储配置:
数据存储:prometheus采用自定义的存储格式将样本数据保存在本地磁盘当中,默认数据存储在prometheus根目录下的/data文件夹中,如图所示:
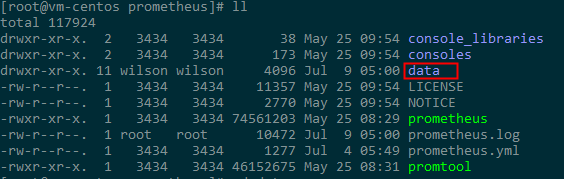
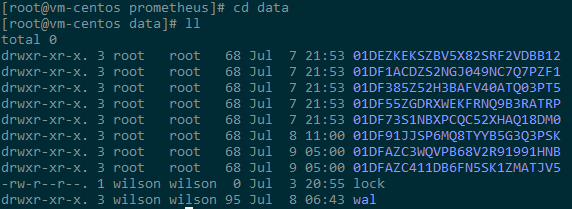
存储说明:Prometheus 按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中。每个块都是一个单独的目录,里面含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。其中索引文件会将指标名称和标签索引到样板数据的时间序列中。此期间如果通过 API 删除时间序列,删除记录会保存在单独的逻辑文件 tombstone 当中。
当前样本数据所在的块会被直接保存在内存中,不会持久化到磁盘中。为了确保 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 启动时会通过预写日志(write-ahead-log(WAL))重新记录,从而恢复数据。预写日志文件保存在 wal 目录中,每个文件大小为 128MB。
wal 文件包括还没有被压缩的原始数据,所以比常规的块文件大得多。一般情况下,Prometheus 会保留三个 wal 文件,但如果有些高负载服务器需要保存两个小时以上的原始数据,wal 文件的数量就会大于 3 个。
Prometheus保存块数据的目录结构如下所示:

Prometheus 的本地存储无法持久化数据,无法灵活扩展。为了保持简单性,定义两个标准接口(远程写remote_write,远程读remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在 Promthues 中称为 Remote Storage。
Prometheus远程存储配置:
Prometheus远程存储的方式有很多种,但是部分只支持写,并不支持读,Elasticsearch就是其中一个,但是我们可以通过中间工具可以实现将数据存储到Elasticsearch和从Elasticsearch中读取数据。在prometheus官网是这样介绍远程读写的:
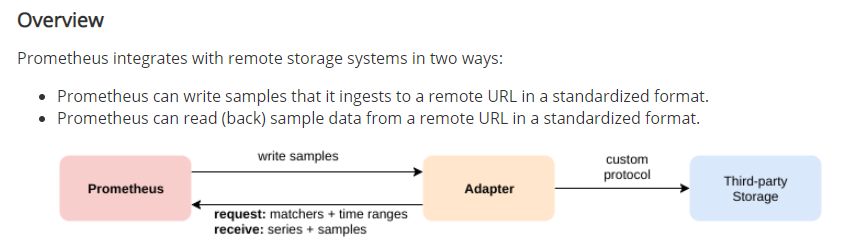
prometheus远程读写数据到Elasticsearch,需要一个对应的adapter来实现,Prometheus-es-adapter 就是实现这个功能的。
Prometheus远程读写到Elasticsearch:
Prometheus-es-adapter在github上可以拉取源码:https://github.com/pwillie/prometheus-es-adapter.git, 这个adapter是Go语言开发的,所有编译运行需要Go语言环境。Go语言环境搭建这里不再描述,只说明编译和运行的步骤。 这里特殊说明一点,go的仓库在国外,可能有些依赖下载不下来,需要配置GOPRAXY环境变量,说明如下:
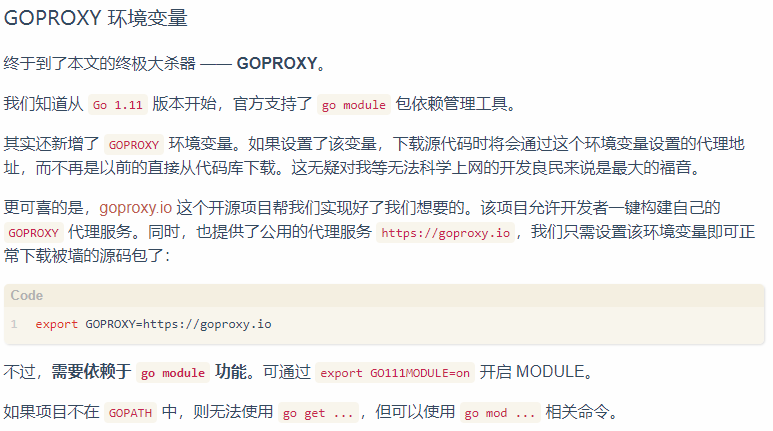
修改配置文件,添加go module和goproxy的配置:
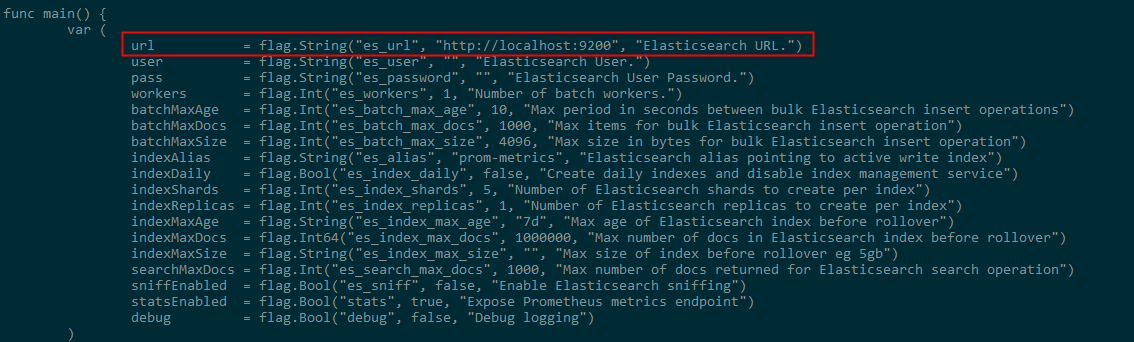
在Go语言环境配置好之后,因为验证时没有在root用户下操作,所以配置的GOPATH为/home/xxx/go,如果是在root用户下操作,安装Go环境之后,默认的GOPATH是/root/go,cd到GOPATH目录下,如果没有src目录则在这个目录下创建一个src文件夹,然后将prometheus-es-adapter 克隆/下载到/src下,也就是/home/xxx/go/src/,或者/root/go/src下,cd到prometheus-es-adapter下,修改/cmd/adapter/main.go文件,默认配置的es信息如下图所示:
然后执行make build命令进行编译,编译完成之后,在当前目录下会生成一个prometheus-es-adapter的可执行文件,这个文件在当前目录下的/release/linux/amd64/文件夹,启动这个可执行文件。
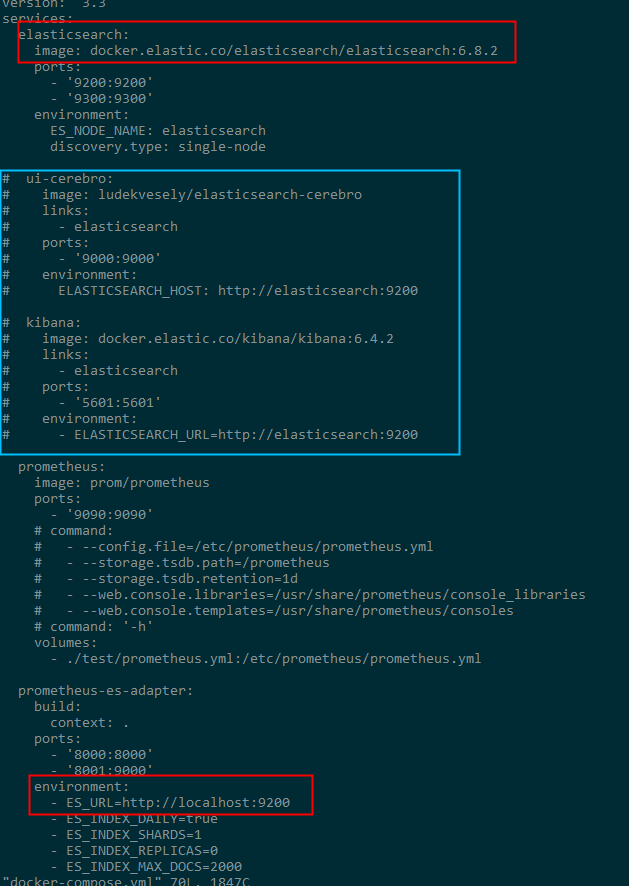
如果是docker启动服务则需要修改docker-compose.yml文件,配置elasticsearch路径、版本等信息,示例如下所示,其中蓝色框中的是自己注释掉的,这个暂且不需要,红色框的是要修改的:
远程读/写的配置很简单,在prometheus.yml中添加remote_write的配置项即可,这里演示配置远程写到Elasticsearch,示例如下:
#远程写
remote_write:
- url: http://192.168.xx.xx:8000/write
#远程读
remote_read:
- url: http://192.168.xx.xx:8000/read
配置完成后,使用kill -HUP pid 就可以热启动,然后访问:http://192.168.xx.xx:8000/read
Prometheus监控配置:
Node_exporter服务器监控:
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。
- 下载node_exporter可以从https://prometheus.io/download/ 获取最新的node exporter版本的二进制包。在prometheus官网提供很多exporter,下载下图红框中的文件,放到要安装的目录下,例如:/usr/local/src目录下;
- 解压缩文件,使用tar -zxvf node_exporter-0.18.1.linux-amd64.tar.gz命令,解压文件,包含一个可执行文件,下图红色框中的文件:
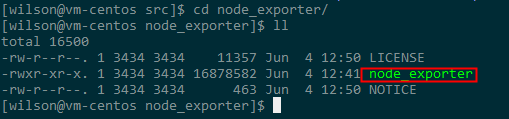
- 进入到node_exporter根目录,输入命令:./node_exporter,启动服务,可以看到下图所示信息即表示启动成功。
另外可以后台启动服务使用命令:nohup ./node\_exporter > node\_exporter.log 2>&1 &,启动成功后,访问[http://192.168.xx.xx:9100](http://192.168.xx.xx:9100)可以看到:
点击mertrics可以看到服务监控信息:

Node_exporter配置到Prometheus:
node_exporter的端口是9100,打开prometheus的配置文件prometheus.yml,在scrape_configs下面添加如下内容,注意这个要跟默认的job_name: 'prometheus’同级配置;
# A scrape configuration containing exactly one endpoint to scrape:
scrape_configs:
\t#node_exporter
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
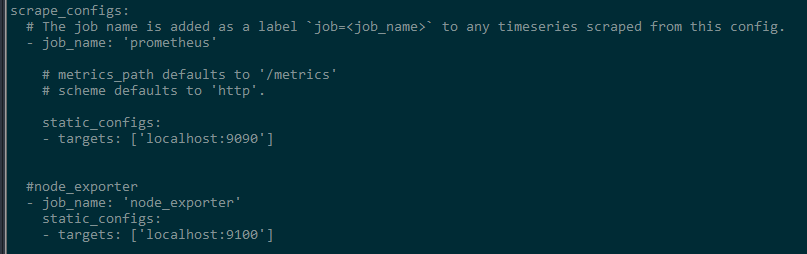
配置好之后,需要重启prometheus服务,重启完成,再次访问http://192.168.xx.xx:9090
点击菜单栏status下的targets可以看到,node_exporter已经出现,并显示状态为UP;因为只部署了一个node_exporter所以看到的是node_exporter(1/1 up);

点击Endpoint下的url(因为所有的服务都在同一机器上,所以这里配置的是localhost)可以看到服务器的监控信息,也就是点击http://192.168.xx.xx:9100 下的metrics同样的页面和内容。
Mysqld_exporter数据库监控:
Mysqld_exporter和Node_exporter类似,也是官网提供的监控插件,在官网可以下载到。
- 通过浏览器访问prometheus官网https://prometheus.io/download/ 获取最新的mysqld_exporter版本的二进制包。下载下图红框中的文件,放到要安装的目录下,例如:/usr/local/src目录下;
- 解压缩文件,使用tar -zxvf mysqld_exporter-0.12.0.linux-amd64.tar.gz命令,解压文件,包含一个可执行文件,下图红色框中的文件(其中mysqld_exporter.log是后台启动指定创建的日志文件,本身不包含此文件):
- 启动可执行文件,使用命令:./mysqld_exporter 看到下图所示信息:

注意红色框中的信息提示当前用户目录root下没有.my.cnf文件,mysqld_exporter监控数据库信息,需要数据库相关的配置,包括url、端口号、用户名和密码,如果这个配置需要配置在当前用户目录下的.my.cnf文件中;
命令cd到用户目录下,当前用户是root 就cd /home/root,然后使用命令:vi .my.cnf这个如果有会打开,如果没有这个文件,保存时会创建。使用ls -la 命令可查看.my.cnf文件是否存在,打开此文件,配置数据库相关信息:
[client]host=192.168.xx.xx
port=3306
user=root
password=root
- 编辑好之后进行保存,然后重新启动mysqld_exporter服务:

此时可以看到错误信息中出现了数据库相关信息,但是拒绝连接,这个是因为数据库没有启动,去后台启动数据库服务后即可,正常连接后如下图所示:

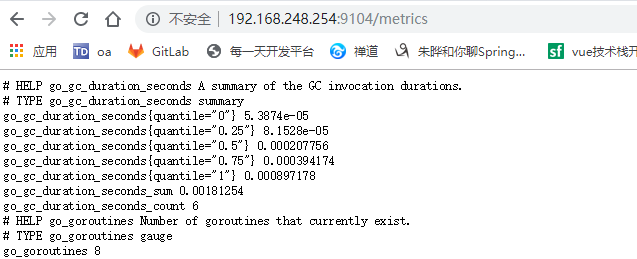
访问http://192.168.xx.xx:9104 查看相关信息:

Mysqld_exporter配置到Prometheus:
配置好mysqld_exporter之后,在prometheus的配置文件prometheus.yml中加入mysqld_exporter的配置,配置信息如下所示:
# A scrape configuration containing exactly one endpoint to scrape:
scrape_configs:
#mysqld_exporter
- job_name: 'mysqld_exporter'
static_configs:
- targets: ['localhost:9104']
然后重启prometheus服务,访问http://192.168.xx.xx:9090 点击菜单栏status下的targets可以看到有关mysqld_exporter的信息,并且状态是UP。

点击连接,可以看到数据库监控信息,如图所示:
Java服务监控:
- 在服务中加入maven依赖:
<!-- actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- prometheus-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
- 在配置文件中配置相关信息:
##=====actuator=====##
management:
endpoints:
web:
exposure:
include: health,info,env,metrics,Prometheus
这里include也可以配置成*,表示所有,配置好之后,启动服务,访问http://192.168.xx.xx:8762/actuator 可看到相关监控信息:

Java服务配置到Prometheus:
服务启动后打开prometheus配置文件prometheus.yml,在配置文件中加入服务监控的相关配置,这里需要注意,和前面的配置相比,多了一个metrics_path的配置项,这里配置的是/actuator/promehteus, 配置信息如下所示:
# A scrape configuration containing exactly one endpoint to scrape:
scrape_configs:
#spring-boot 这里命名为spring-boot
- job_name: 'spring-boot'
metrics_path: '/actuator/prometheus'
static_configs:
\t\t- targets: ['192.168.xx.xx:8762']
metrics_path说明:
prometheus处理监控信息的格式是固定的如下图所示:
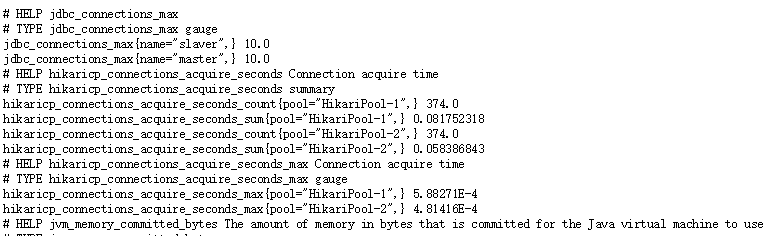
prometheus默认的监控接口是/metrics,访问http://192.168.xx.xx:8762/actuator/metrics 看到如下信息:

上图中的数据格式prometheus是无法处理的,所以不能在prometheus配置中使用默认的接口,访问http://192.168.xx.xx:8762/actuator/prometheus 可以看到:
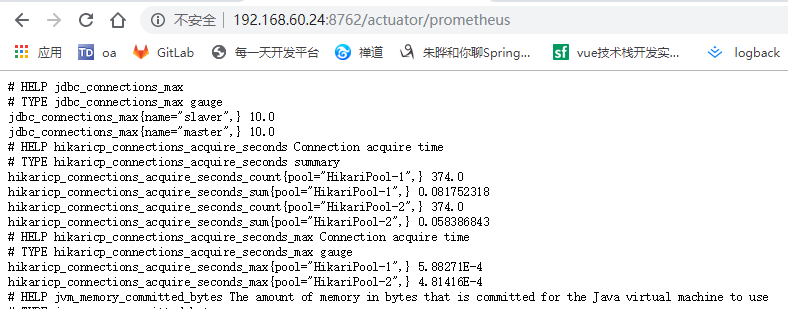
这个是prometheus可以处理的,所以要配置metrics_path为/actuator/prometheus的接口。配置完成后,访问http://192.168.xx.xx:9090 点击菜单栏status下的targets可以看到有关spring_boot的信息,并且状态是UP,如果没有配置metrics_path,服务状态则是DOWN。

Prometheus告警配置:
Prometheus 告警配置参考prometheus.yml配置文档中的描述可以知道,告警规则可以是外部的YAML文件。在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容;
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警;
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
Prometheus告警规则:
Prometheus告警规则是基于PromQL表达式定义的,示例如下:
groups:
- name: node_alert
rules:
# Alert for any instance that is unreachable for > 10 seconds.
- alert: Instance Down
expr: up == 0
for: 10s
annotations:
summary: "Instance {
{ $labels.instance }} down"
description: "{
{ $labels.instance }} of job {
{ $labels.job }} has been down."
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。通过 labels.name 变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。一条告警规则主要由以下几部分组成:
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
按照PromQl语法配置一个告警规则,定义alert_rules.yml文件,将示例中的语句复制到alert_rules.yml文件中,保存,然后在prometheus的配置文件中,规则配置项添加alert_rules.yml的文件路径配置,完成之后使用命令:./promtool check rules ./ alert_rules.yml 检查规则是否正确,简称正确,一切完成后重启prometheus,访问http://192.168.xx.xx:9090/rules 可以看到配置的告警信息:

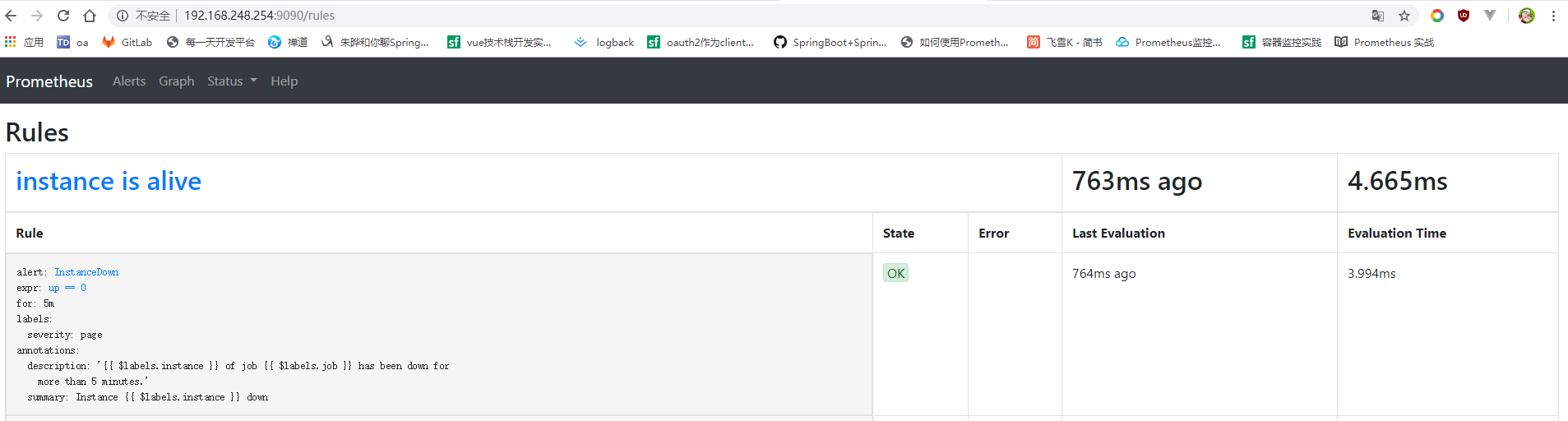
当告警规则触发时,alerts的state会变成PENDING,如果后告警条件持续满足配置的时间,告警状态为FIRING

Alertmanager配置到Prometheus:
Prometheus可以配置告警规则,并触发告警配置,但是只能在页面看到状态的变化,无法发送告警通知,alertmanager结合prometheus可以做到更多。
-
通过浏览器访问prometheus官网https://prometheus.io/download/ 获取最新的alertmanager。下载下图红框中的文件,放到要安装的目录下,例如:/usr/local/src目录下;
-
执行解压缩命令,解压下载的alertmanager-0.18.0.linux-amd64.tar.gz文件,里面包含alertmanager的可执行文件alertmanager,和配置文件alertmanager.yml

- 启动alertmanager服务,默认端口为9093,访问http://192.168.xx.xx:9093 可以看到相关的信息,点击status查看配置信息:

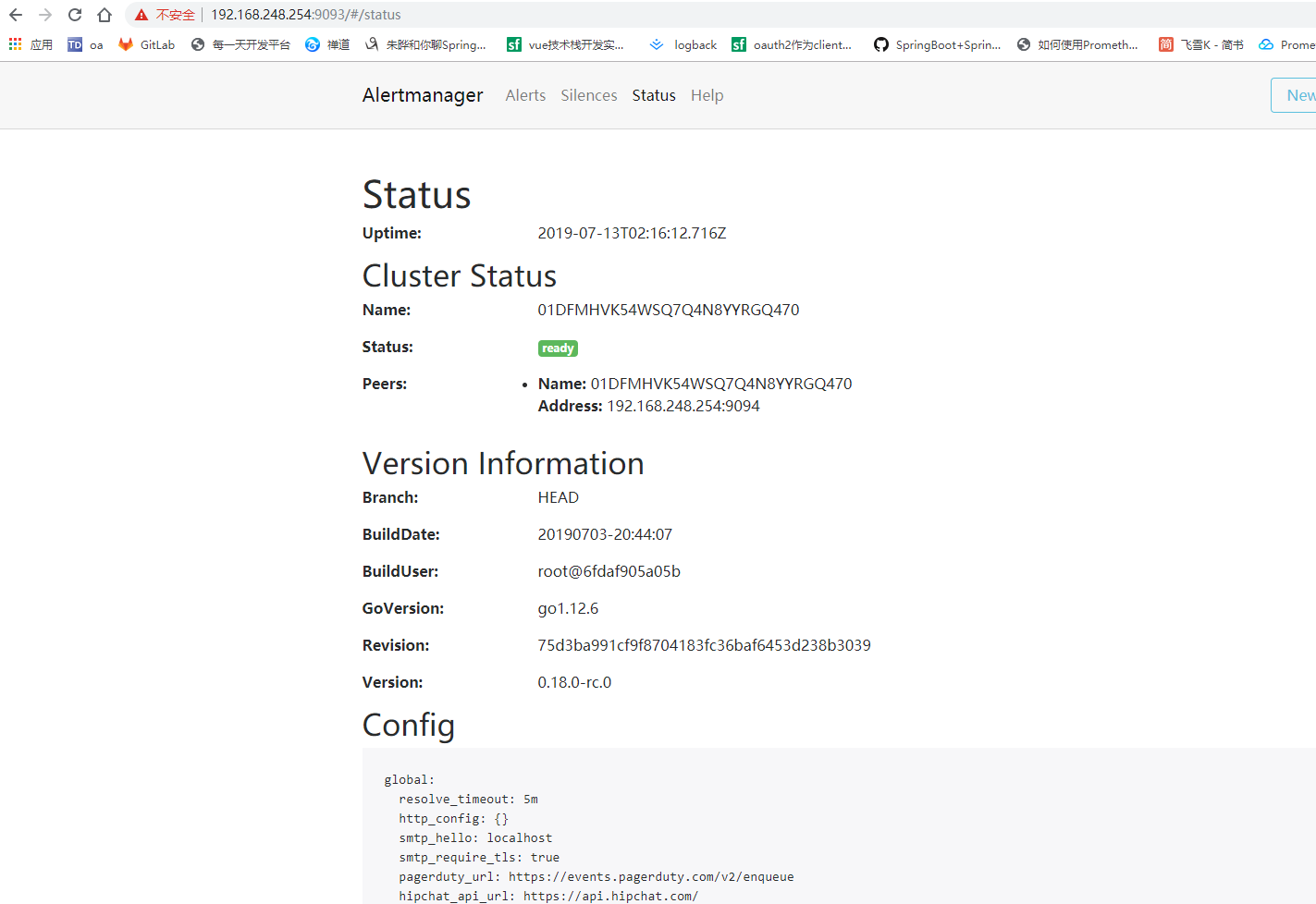
- 打开alertmanager.yml文件,下载邮件通知模板,添加邮件配置信息,内容示例如下所示:
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'sxxasd' #这里需要得是客户端授权登录密码,非账号登录密码
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: team-X-mails
receivers:
- name: 'team-X-mails'
email_configs:
- to: '[email protected]'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
templates:
- 'default.tmpl'
模板下载:
wget https://raw.githubusercontent.com/prometheus/alertmanager/master/template/default.tmpl
- 配置完成后重启服务,刷新http://192.168.xx.xx:9093/status 可以看到配置信息已经更新:
当告警规则触发后,alertmanager会收到来自prometheus的告警信息,并且会发送告警通知(这里配置的是邮件通知,所以会):
Grafana安装:
虽然prometheus可以进行一些数据的查看,但是没有只能看到一堆的数据,分析起来复杂,且不直观,grafana是一个可视化工具,可以根据需要安装各种功能分析和展示插件来直观的展示数据信息;
- 安装grafana的方式很多,参考:https://grafana.com/docs/installation/rpm/ 为了方便直接使用 yum 安装:
sudo yum install [https://dl.grafana.com/oss/release/grafana-5.4.2-1.x86_64.rpm](https://dl.grafana.com/oss/release/grafana-5.4.2-1.x86_64.rpm)
- 安装完成后执行:sudo service grafana-server start启动grafana服务,也可以通过systemctl start grafana-server启动(在使用此命令之前先执行一次systemctl daemon-reload),启动之后查看状态:systemctl status grafana-server;
- Grafana默认端口号为3000,启动后访问http://192.168.xx.xx:3000 ,可看到下图画面,默认的账号密码是admin/admin;

Grafana 配置数据源:
- 进入首页,点击add data source选项,进入数据源配置页面:

- 选择prometheus作为数据源配置,点击prometheus后进入数据源配置页面,如下图所示:
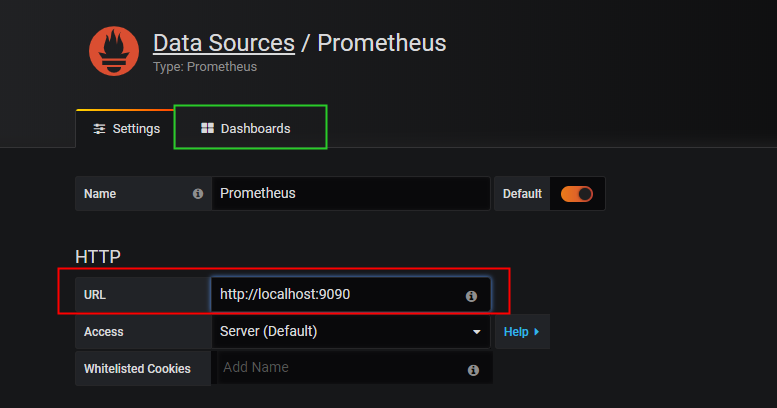
- 在红色框中配置相关的信息,这里grafana和prometheus在同一台机器上,所以这里配置http://localhost:9090 ,填写完成后,点击save and test,然后点击绿色框中的dashbords选项,选择prometheus 2.0 stats点击后面的import。
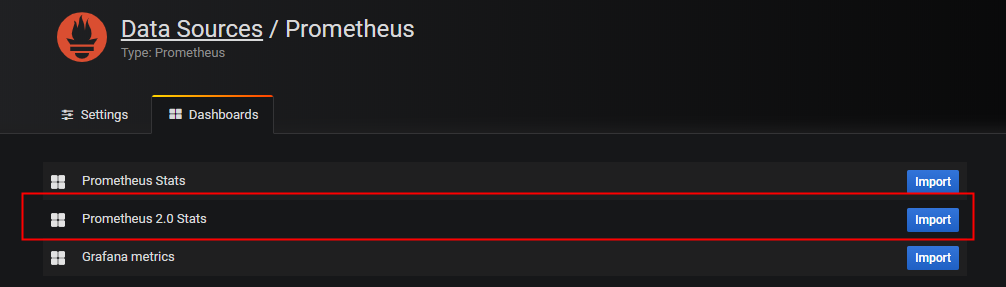
- Import之后,在首页中,选择配置的prometheus 2.0 stats,就可以看到数据展示。
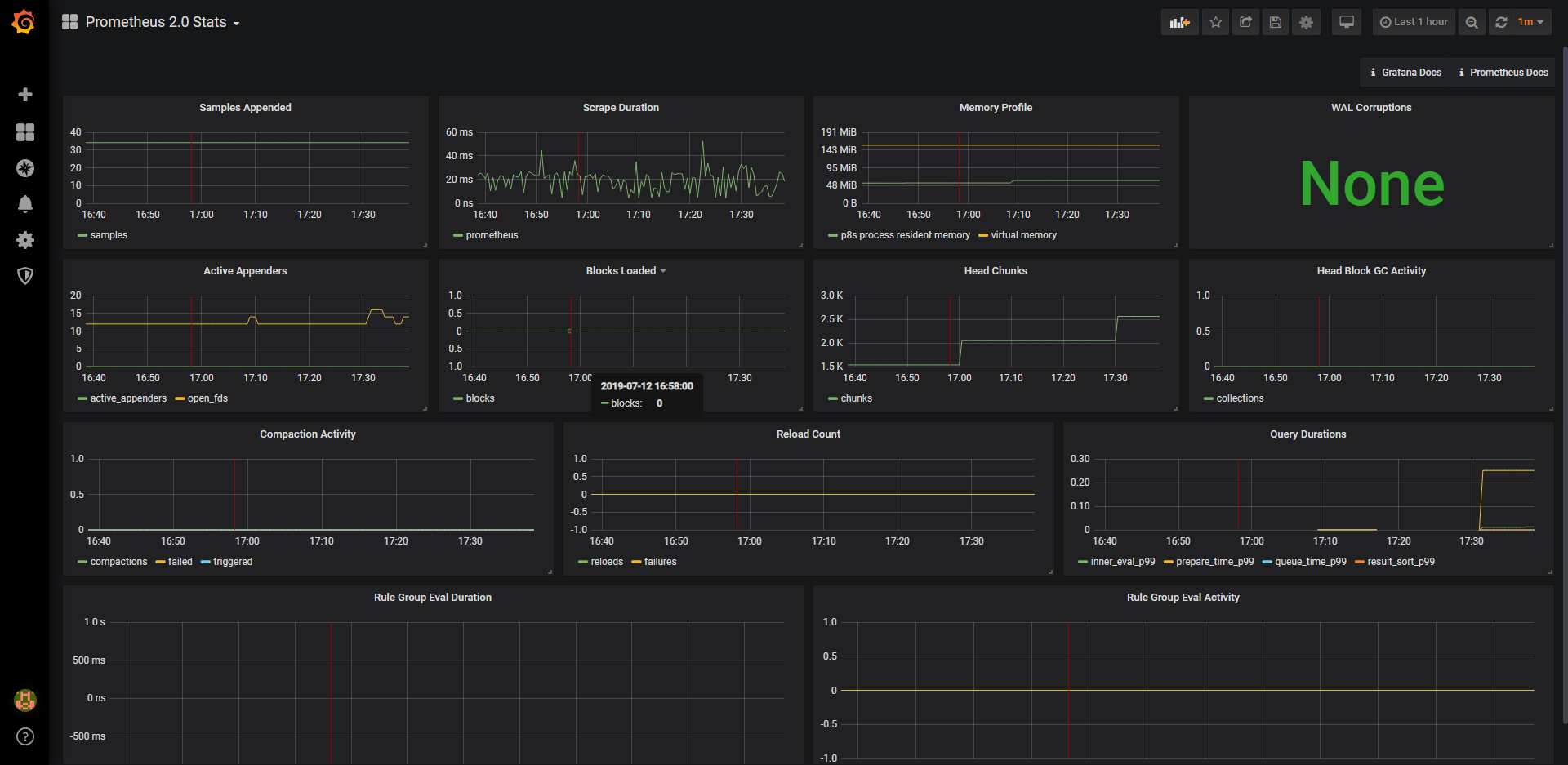
Grafana dashboards添加:
点击左侧栏中的+图标下的import,在页面中输入grafana labs的dashboards下的插件id(node_exporter:1860, mysqld_exporter: 6239, jvm: 4701/9568),会自动跳转至配置页,选择数据源为prometheus,然后点击import。

操作完成,服务运行一段时间之后可以看到相关的数据统计:

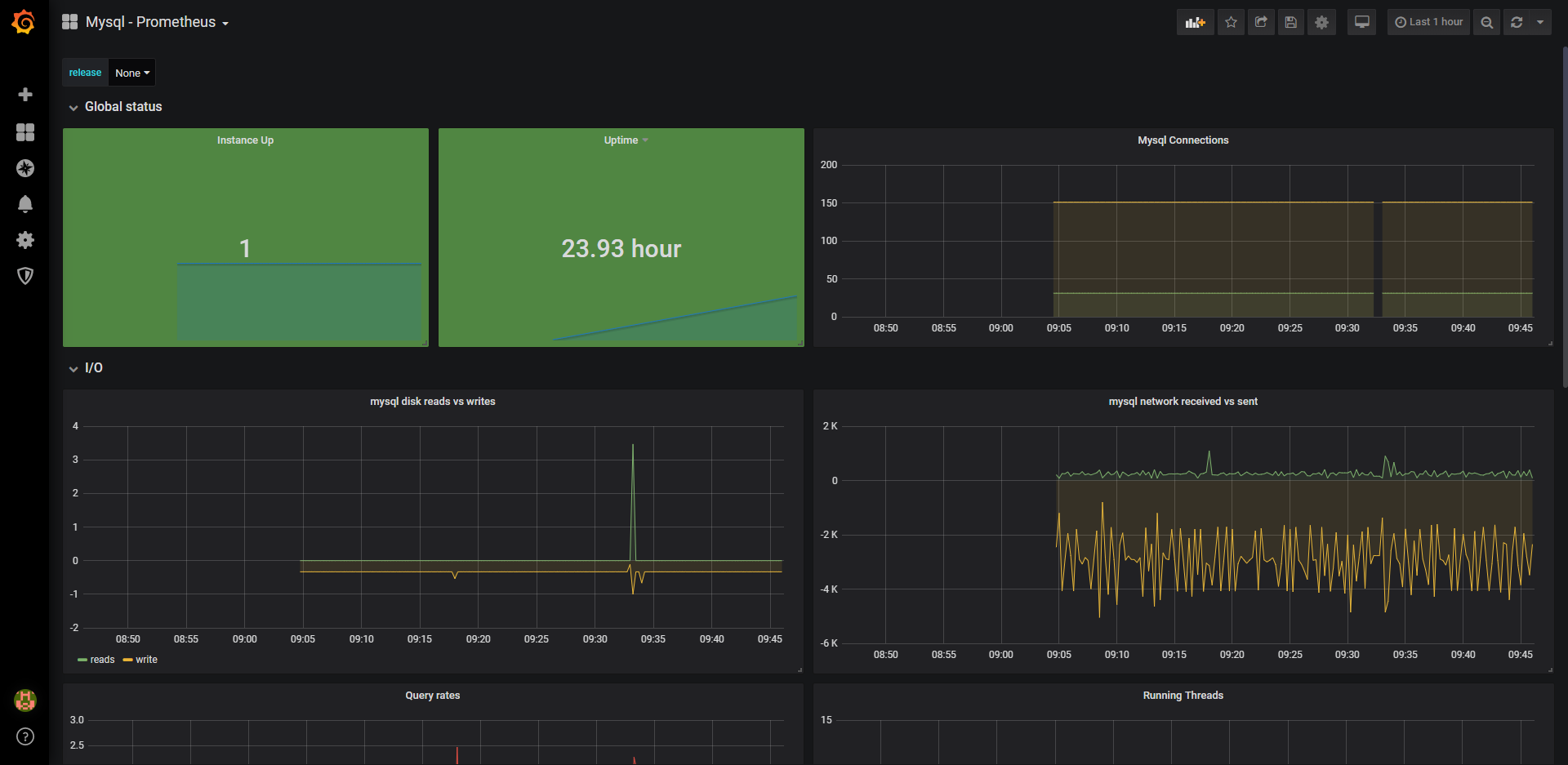
注意红色框中,容器名称时没有的,这里需要说明得是,使用4701这个dashboards时,需要在spring boot配置文件中增加一些配置,两种配置二选一即可: